Abstract
The subpopulation shifting challenge, known as some subpopulations of a category that are not seen during training, severely limits the classification performance of the state-of-the-art convolutional neural networks. Thus, to mitigate this practical issue, we explore incremental subpopulation learning (ISL) to adapt the original model via incrementally learning the unseen subpopulations without retaining the seen population data. However, striking a great balance between subpopulation learning and seen population forgetting is the main challenge in ISL but is not well studied by existing approaches. These incremental learners simply use a pre-defined and fixed hyperparameter to balance the learning objective and forgetting regularization, but their learning is usually biased towards either side in the long run. In this paper, we propose a novel two-stage learning model to explicitly disentangle the acquisition and forgetting for achieving a better balance between subpopulation learning and seen population forgetting: in the first ''gain-acquisition'' stage, we progressively learn a new classifier based on the margin-enforce loss, which enforces the hard samples and hard population to have a larger weight for classifier updating and avoid uniformly updating all the population; in the second ''counter-forgetting'' stage, we search for the appropriate combination of the new and old classifiers by optimizing a novel objective based on proxies of forgetting and acquisition estimation. We benchmark the representative and state-of-the-art non-exemplar-based incremental learning methods on a large-scale subpopulation shifting dataset for the first time. Under almost all the challenging ISL protocols, we significantly outperform the other methods by a large margin, demonstrating our superiority to alleviate the subpopulation shifting problem.
Background
Subpopulations are widely existed in the real world. A visual category (colored ellipse) contains a large number of subpopulations (denoted by each image) which are semantically similar and share common visual characteristics to be in the same category, while they also have large differences in appearances, shape, context, etc. Each subpopulation is also a distribution with sufficient variations, e.g., cover thousands of distinct objects belonging to this subpopulation in nature.
(A) and (B) show the difference between the ISL and incremental domain learning (IDL): in IDL (includes NI and CDA), the new distribution is only the manipulation of the existing subpopulations' distributions (e.g., the same subpopulation in different visual domains), but no new unseen subpopulations are introduced; Instead in ISL, the new distribution is the totally new and unseen subpopulation that is not existed in the distribution of a category before. Concrete examples are in our supplementary. (C) shows our method can gradually acquire the unseen subpopulations during ISL.

Method
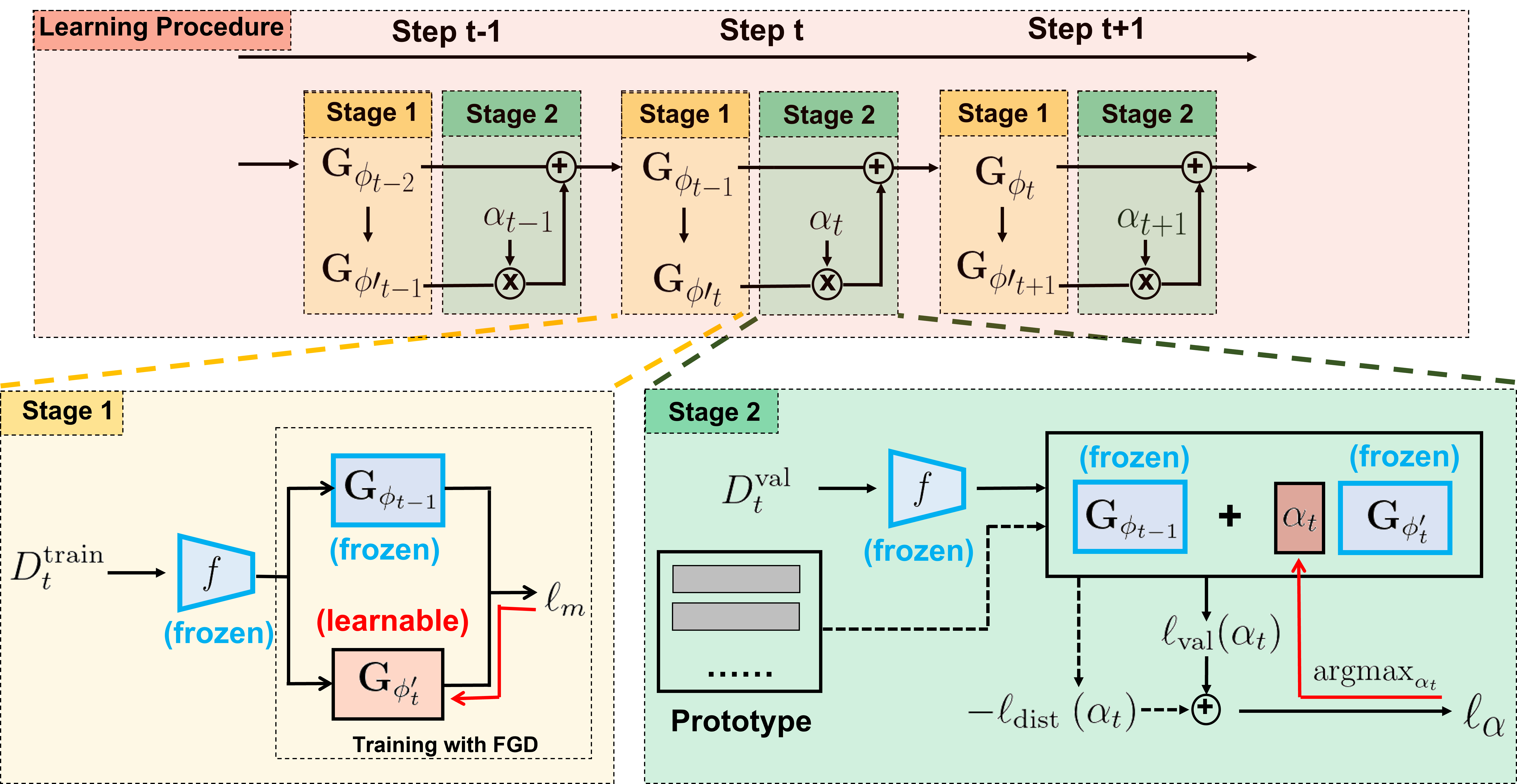
During the incremental subpopulation learning procedure, in each incremental step $t$ we obtain the classifier $\mathrm{G}_{\phi_{t}}$ for the model $F_{t}$ by two stages. In Stage-1, we learn a new classifier $\mathrm{G}_{\phi_{t}^{\prime}}$ via functional gradient descent (FGD) of Eqn.3. In Stage-2, we obtain $\mathrm{G}_{\phi_{t}}$ by combining the new and old classifiers linearly via a proper $\alpha_{t}$ solved by Eqn.10 to balance the acquisition and forgetting approximately.
Experimental results
Average top-1 test accuracy in each step under 3 protocols of Entity-13.
Average top-1 test accuracy in each step under 3 protocols of Entity-30.
BibTeX
@inproceedings{liang2022balancing,
title={Balancing Between Forgetting and Acquisition in Incremental Subpopulation Learning},
author={Liang, Mingfu and Zhou, Jiahuan and Wei, Wei and Wu, Ying},
booktitle={European Conference on Computer Vision},
pages={364--380},
year={2022},
organization={Springer}
}